Baba Is AI
Baba Is AI is a benchmark environment based on the puzzle game “Baba Is You”. In this gridworld game, players interact with various objects and textual rule blocks to achieve specific goals. The unique aspect of Baba Is AI is that the rules of the game can be manipulated and rearranged by the player, creating a dynamic environment where agents must identify relevant objects and rules and then manipulate them to change or create new rules to succeed. This benchmark allows researchers to explore a broader notion of generalization compared to current benchmarks, as it requires agents to not only learn and follow the rules but also to combine previously seen rules in novel ways. Agents are tested on 40 different puzzle levels.
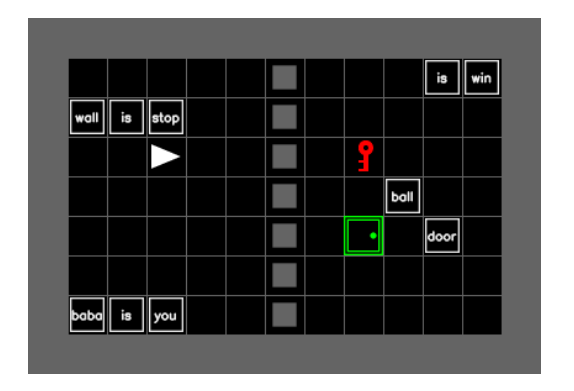
Baba Is AI Language Wrapper
To enable interaction with language models, we made a custom language wrapper for Baba Is AI. It constructs language observation from active rules and creates a description by formatting object positions relative to the player. We don’t provide the solution for the agent and don’t specify grid boundaries in the text-only experiments.
Baba Is AI Results
Standard errors are computed using 5 seeds for each of the 40 Baba Is AI tasks. Surprisingly, the Llama models lead, with Llama 3.2 90B surpassing GPT-4o by a 10% margin in language-only mode. Once again, when vision is added, model performance suffers, with only Gemini-1.5-Pro remaining stable.
LLM results
Model |
Average Progress (%) |
|---|---|
llama-3.2-90B-it |
43.90 ± 3.47 |
llama-3.1-70B-it |
40.00 ± 3.42 |
gpt-4o |
33.66 ± 3.30 |
gemini-1.5-pro |
32.02 ± 3.26 |
gpt-4o-mini |
15.60 ± 2.53 |
llama-3.2-11B-it |
15.60 ± 2.50 |
gemini-1.5-flash |
12.80 ± 2.33 |
VLM results
Model |
Average Progress (%) |
|---|---|
gemini-1.5-pro |
31.40 ± 3.24 |
llama-3.2-90B-it |
21.90 ± 2.89 |
gpt-4o |
18.62 ± 2.72 |
gpt-4o-mini |
16.41 ± 2.59 |
gemini-1.5-flash |
8.30 ± 1.93 |
llama-3.2-11B-it |
5.76 ± 1.63 |
Observations
TODO